Hier im Blog möchte ich dazu schwerpunktmäßig die Vorgehensweise bei unserer Social-Media-Analyse vorstellen.
Die Ergebnisse der Studie werden kurz im Abstract zusammengefasst. Die vollständige Studie ist erhältlich bei Reputation Control.
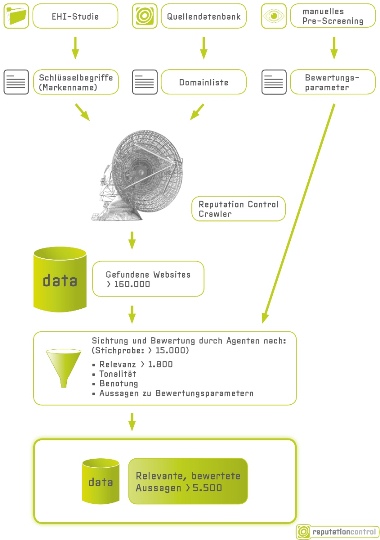
Die beiden wesentlichen Schritte sind zum einen ein automatisiertes Suchen und Speichern der potenziell relevanten Beiträge und zum anderen eine Sichtung und Bewertung der gefundenen Beiträge durch Mitarbeiter des Reputation-Control-Teams.
Beiträge finden
Für die Suche, Speicherung und Bewertung wird die Reputation-Control-Software verwendet: Ein Crawler, eine Datenbank und eine Oberfläche für die Sichtung und Bewertung, die wir gemeinsam mit einem technischen Dienstleister entwickeln.
Die Suchbegriffe ergeben sich aus den Markennamen (und gängigen Falschschreibungen) der größten Handelsketten (gemessen an Umsatz oder Filialzahl) gemäß den aktuellen Daten des EHI Retail Institutes. Da wir demnach über 40 Markennamen untersuchen wollten (mit noch deutlich mehr Schreibweisen), entschieden wir uns gegen ein offenes Screening sondern führten ein gezieltes Domain-Monitoring durch. Analysiert wurden dabei diejenigen Domains aus der kontinuierlich aktualisierten Reputation-Control-Quellendatenbank, auf denen in aktuellen Kundenprojekten und in der Studie des letzten Jahres relevante Beiträge für die untersuchten Branchen gefunden wurden.
Beiträge sichten und bewerten
Die Bewertungsparameter, mit denen die Agenten dann die Aussagen in Funden klassifizieren, wurden schließlich über ein manuelles Pre-Screening beispielhafter Erfahrungsberichte identifiziert.
Die zu sichtende Stichprobe haben wir dabei so gewählt, dass Marken und Domains gemäß ihren Anteilen an den Gesamtfunden repräsentiert werden und Beiträge mit höherem Suchmaschinenranking bevorzugt gesichtet werden. Die Auswahl der gesichteten Funde erfolgte innerhalb dieser Parameter zufällig.
Anschließend haben sich meine Kollegen über 15.000 Seiten angesehen, Erfahrungsberichte studiert, Forenthreads gelesen, Videos überprüft und so weiter. Dabei haben Sie jeden Fund daraufhin untersucht, ob er Aussagen zu den jeweiligen Marken und den zuvor definierten Bewertungsparametern enthält und dies in unserer Software entsprechend getagged. Gleichzeitig wurden die Veröffentlichungsdaten und formale Bewertungen (Sternchenskalen, Schulnoten etc.) extrahiert.
Kundenaussage als kleinste Einheit
Eine kurze Antwort auf gutefrage.net (z.B. F: „Wo kann man günstig Möbel kaufen?“ A: „Dänisches Bettenlager“) ist weniger differenziert als ein strukturierter Erfahrungsbericht auf ciao.de. Dafür kommen in einer lebendigen Community-Diskussion (z.B. auf netmoms.de) viel mehr Meinungen zu verschiedenen Marken zusammen. Um diese Vielfältigkeit und unterschiedliche Gewichtung der einzelnen Funde angemessen abbilden zu können, haben wir Kundenaussagen als kleinste Maßeinheit verwendet.
Eine Methodik, die sich auch in Kundenprojekten bewährt hat. So enthält ein langer Erfahrungsbericht meist viele Aussagen zu unterschiedlichen Aspekten (z.B. Preis, Qualität, Beratung, Freundlichkeit, Parkplatzsituation etc.). In einer Forumsdiskussion werden dagegen vielleicht nicht alle Aspekte bewertet, sondern es geht möglicherweise nur um Preis und Qualität – dafür äußern sich hier gleich mehrere Nutzer in unterschiedlichen Tonalitäten zu diesen Themen.
Mit dieser Systematik zählen wir Aussagen zu einzelnen Bewertungskriterien und versehen diese mit einer Tonalität. Erst dadurch entsteht in der Summe ein differenziertes Meinungsbild. Ein Beitrag wie „Natürlich sind die Möbel da etwas teurer, aber sie sind eben auch gut verarbeitet und halten länger.“ ist ja nicht an sich positiv oder negativ, sondern er enthält zwei Aussagen. Die Preis-Aussage ist negativ, die Qualitätsaussage ist positiv. Eine automatische Sentiment-Analyse kann diese Differenzierung nicht leisten.
Facebook- und Twitter-Monitoring für Analyse zu oberflächlich
Wenn man sich die Verteilung der Aussagen auf die Quellen ansieht, ergibt sich je nach Branche ein unterschiedliches Bild:
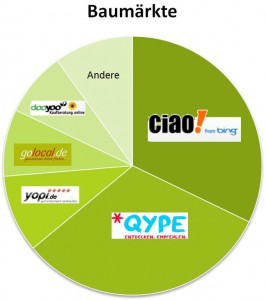
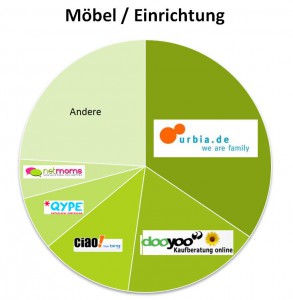

Qype, ciao, dooyoo aber eben auch urbia spielen jeweils wichtige Rollen. Hieran wird übrigens gut deutlich, warum Google-Alerts oder Twitter- und Facebook-Monitoring für eine Social-Media-Analyse zu wenig sind. Als Frühwarnsystem für potenzielle Krisen sind diese Instrumente natürlich wichtig, aber die interessanten Diskussionen im Deepweb erfassen sie nicht. Diese sind für die Meinungsbildung der Zielgruppe aber oft entscheidend.
Preis-Vorhersage mit Social-Media-Analyse?
Ende Juni hatte ich die ersten Ergebnisse auf der Stores 2011 in Bonn präsentiert. Gleichzeitig kürten dort der Handelsverband Deutschland und das Handelsblatt die Händler des Jahres. Die Auszeichnung fußt auf einer umfangreichen Online-Befragung mit rund 200.000 Teilnehmern. Es hat uns natürlich sehr gefreut, dass die Ergebnisse in vielen Punkten mit unserer Studie übereinstimmen.
So ist z.B. IKEA Kundenliebling in der Branche „Wohnen“ und Ernsting’s family – erneut Gewinner der Kategorie „Baby- & Kindermode“ – wurde ja schon letztes Jahr von Reputation Control als bleibtester Händler in der Bekleidungsbranche ausgemacht. Es gibt allerdings auch Abweichungen: In der Branche Baumärkte gewann Bauhaus die Befragung, während in Social Media Hornbach und Obi besser bewertet werden.
Verfasser: Hans-Joachim Gras
Heiß auf Insider-Infos?
Immer up to date: Unser Newsletter versorgt dich einmal monatlich mit brandneuen Trends und Innovationen aus der Kommunikationswelt.